PRoject
Building an AI-powered Financial Report Chatbot
STACK: Stack: LangChain, FAISS, OpenAI (text-embedding-ada-002 + GPT-4o Mini), FastAPI, Vanilla JavaScript, Docker, Render
AI adoption is happening faster than ever, with companies racing to integrate the latest tools wherever possible. But the real winners will be those that adopt AI thoughtfully, e.g. making it easier for every employee to access and understand relevant data, and to work smarter without risking data privacy.
Building in-house solutions keeps valuable company knowledge within your walls and prevents the temptation for employees to paste confidential insights into public tools like ChatGPT.
This article walks through how I built an end-to-end RAG system using open-source and API-based tools.
The Problem: Information Overload
Financial analysts, investors, and many businesses in general routinely face a common challenge: extracting specific insights from hundreds or thousands of pages of reports.
Traditional approaches fall short:
Manual search: Reading through documents takes hours
Ctrl+F keyword search: Only finds exact matches, misses context
Generic ChatGPT: No access to internal documents
Using RAG: The Best of Both Worlds
Retrieval-Augmented Generation (RAG) both bridges the information gap and reduces information overload by:
1. Retrieving relevant information from the documents
2. Augmenting the AI with that specific context
3. Generating natural language answers grounded in your data
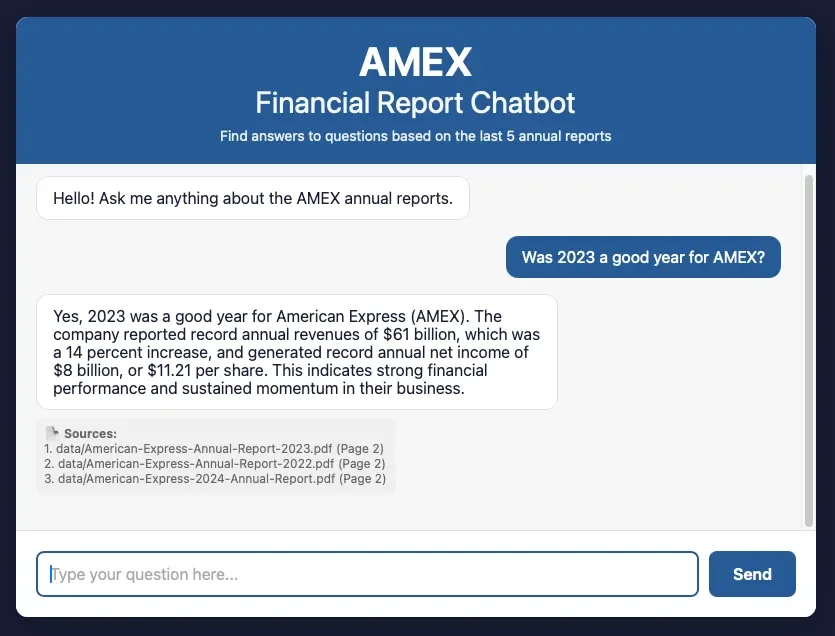
TL;DR: The AMEX Annual Report Chatbot
To create a small-scale example, I used the last five years of publicly available annual reports from AMEX to create a chatbot style web-app that uses AI to answer questions from one source only — the reports themselves.
Architecture Overview
My system consists of three main phases:
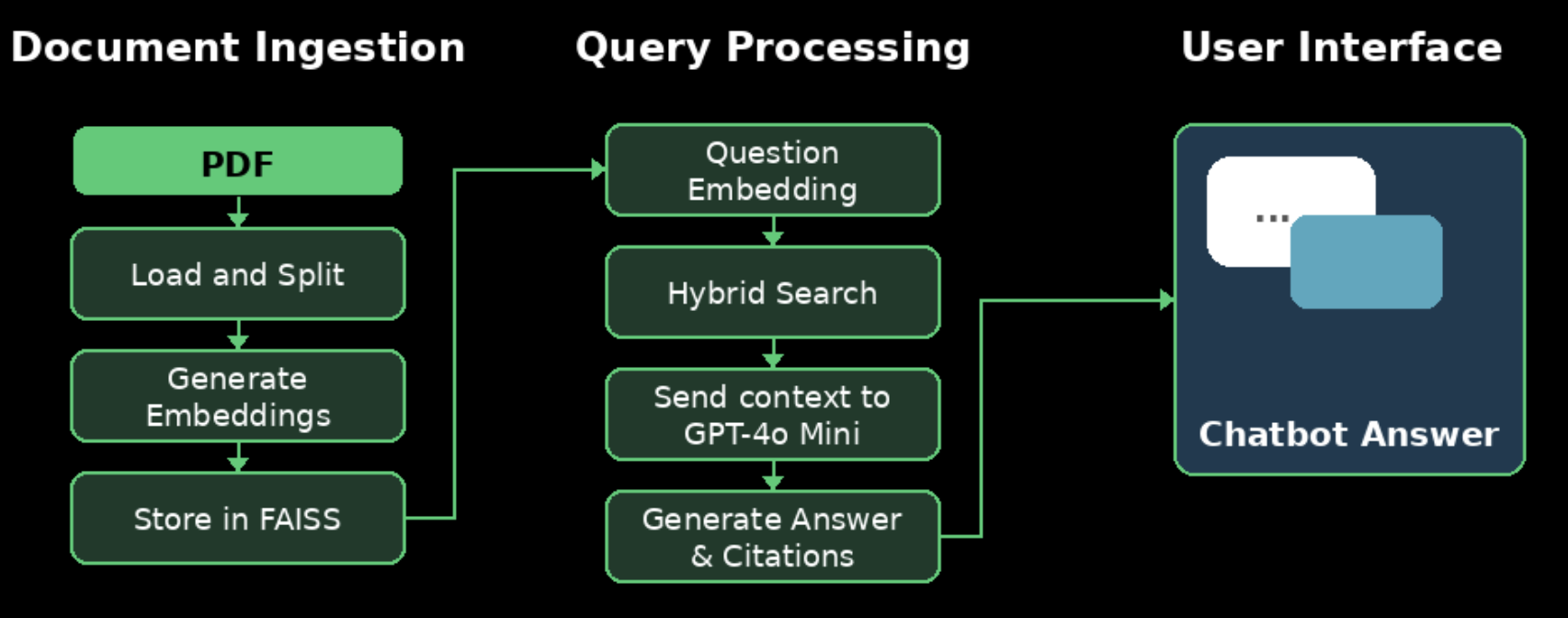
Phase 1: Document Ingestion (One-Time Setup)
Load PDFs and extract text
Split into manageable chunks with overlap
Generate embeddings using OpenAI’s text-embedding-ada-002
Store in FAISS vector database
Phase 2: Query Processing (Real-Time)
Convert user question to embedding
Perform hybrid search (semantic + keyword filtering)
Feed relevant context to GPT-4o Mini
Return answer with source citations
Phase 3: User Interface
Clean, chat-style web interface
FastAPI backend with RESTful endpoints
Deployed on Render with continuous deployment with minimal downtime
The Technical Implementation
1. Document Processing and Chunking
The first challenge was handling 950+ pages efficiently. I used LangChain’s pre-tuned parameters:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size chunk_size =1000 # 2-3 paragraphs
chunk_overlap chunk_overlap =200 # Preserve context across boundaries
)
chunks = text_splitter.split_documents(documents documents)
# Result: 4,021 searchable chunks
Why 1000 characters? This balances context preservation with token efficiency. Too small loses meaning; too large exceeds model limits.
Why 200-character overlap? This is crucial for handling page boundaries. When text spans pages, the overlap ensures no context is lost.
2. Embeddings: Converting Meaning into Math
Embeddings transform text into 1,536-dimensional vectors that represent semantic meaning. Similar concepts cluster together in this high-dimensional space:
“revenue” and “income” → vectors point in similar directions
“profit” and “loss” → vectors point in opposite directions
This enables the system to understand that a question about “earnings” should retrieve chunks about “net income”, even though the words differ.
Generating 4,021 embeddings is a very low-cost one time investment — approximately $0.30.
3. FAISS: Lightning-Fast Similarity Search
FAISS (Facebook AI Similarity Search) is what makes real-time search feasible. Instead of comparing each query against 4,021 chunks sequentially, FAISS builds an index structure that narrows the search space intelligently using approximate nearest neighbor (ANN).
4. Hybrid Search: Solving the Hallucination Problem
Early testing revealed a critical point: when asked about data from a specific year, the system needed to prioritize insights from that year’s report over secondary mentions in subsequent years.
The solution: Hybrid search combining semantic similarity with keyword filtering.
def extract_year_from_question(question: str):
year_pattern = r'\b(202[0-4])\b'
match = re.search(year_pattern, question)
return match.group(1) if match else None
# Perform broad semantic search
semantic_results = vectorstore.similarity_search(question, k=10)
# If year detected, prioritize year specific documents
if target_year:
year_filtered = [doc for doc in semantic_results
if target_year in doc.metadata['source']]
other_results = [doc for doc in semantic_results
if target_year not in doc.metadata['source']]
# Prioritize year specific docs, fill remainder with others
final_docs = year_filtered[:5] + other_results[:max(0, 3-len(year_filtered))]
else:
final_docs = semantic_results[:5]
5. Integrating GPT-4o Mini for Answer Generation
After retrieving relevant document chunks, the system needs to generate coherent, natural language answers. This is where GPT-4o Mini comes in.
The LLM Configuration:
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
Why these choices?
GPT-4o Mini: OpenAI’s small model offering GPT-4-class reasoning at a fraction of the cost. Significantly more accurate than GPT-3.5 while remaining cost-effective (~$0.0015/query).
temperature=0: Produces deterministic, factual responses. Higher temperatures add creativity but increase hallucination risk.
The Prompt Strategy:
The system constructs a careful prompt that combines retrieved context with the user’s question:
# Build context from retrieved chunks
context = "\n\n".join([doc.page_content for doc in final_docs])
# Create the prompt
prompt = f"""Use the following context to answer the question.
If you don't know the answer based on the context, say so.
Context:
{context}
Question: {question}
Answer:"""
# Get answer from LLM
response = llm.predict(prompt)
What GPT-4o Mini receives:
Use the following context to answer the question...
Context:
[Chunk 1 from 2021 Report, Page 5]:
"...delivered net income of $8.1 billion and diluted earnings
per share of $10.02..."
[Chunk 2 from 2021 Report, Page 12]:
"...returned $9 billion of capital to shareholders through
dividends and share repurchases..."
[Chunk 3 from 2021 Report, Page 18]:
"...total revenues net of interest expense increased 17%
to $42.4 billion..."
[Chunk 4 from 2021 Report, Page 23]:
"...card member spending increased 24% year-over-year..."
[Chunk 5 from 2021 Report, Page 31]:
"...provision for credit losses decreased significantly..."
Question: What was AMEX's net income in 2021?
Answer:
GPT-4o Mini’s Response: “American Express delivered net income of $8.1 billion in 2021, with diluted earnings per share of $10.02.”
Why This Model Works Particularly Well:
GPT-4 level reasoning: Better at understanding financial terminology and complex queries
Reduced hallucination: More reliable at sticking to provided context than GPT-3.5
Cost-effective: 60% cheaper than GPT-4, only slightly more than GPT-3.5
More context window: Retrieves 5 chunks, providing rich context for better answers
Token efficiency: ~700–900 tokens per query (question + 5 chunks + response)
Preventing Hallucinations:
Several layers improve accuracy:
Temperature=0: Deterministic outputs
Explicit instructions: “Use only the context provided”
Limited context window: Model can’t invent facts outside the 5 chunks
Source citations: Users can verify answers against original documents
GPT-4o Mini’s training: Better instruction-following than previous models
Cost per Query Breakdown:
Input tokens (~700): $0.000105 (GPT-4o Mini: $0.150/1M tokens)
Output tokens (~200): $0.000120 (GPT-4o Mini: $0.600/1M tokens)
Total per query: ~$0.00023
At this price point, even 10,000 queries/month costs only ~$2.30, making the system very economical while maintaining GPT-4 level quality.
The Full-Stack Application
Backend (FastAPI):
RESTful API with automatic documentation
Pydantic models for request/response validation
CORS middleware for cross-origin requests
Health check endpoints for monitoring
Frontend (Vanilla JavaScript):
Chat-style interface with message history
Real-time loading indicators
Source citations for transparency
Responsive design for mobile/desktop
Deployment (Render):
Containerized with Docker
Automatic deploys from GitHub
Environment variables for API key security
free tier with automatic restarts on demand
Security Considerations:
This is a portfolio demonstration project and has not undergone formal security review. While basic security practices are implemented (environment variables for API keys, HTTPS via Render), it is not hardened for production use with sensitive data or public access at scale.
For enterprise deployment, collaboration with security professionals would be essential to implement appropriate authentication, access controls, rate limiting, and compliance measures based on specific use cases and requirements.
Real-World Applications
This architecture isn’t limited to financial reports. The same approach works for:
Legal document analysis: Contract review, case law research
Medical records: Patient history queries with HIPAA compliance
Technical documentation: API docs, internal wikis
Customer support: Knowledge base automation
Research papers: Academic literature review
Corporate knowledge: Internal policy and procedure queries
Future Enhancements
Several enhancements could add value to the current demo:
Multi-Modal Support: add support for tables, charts, and images using vision models
Conversational Memory: maintain context across multiple questions in a session
Fine-Tuned Models: train embeddings specifically on financial terminology
Advanced Analytics: track query patterns to identify common user needs
Conclusion: The Future Is Retrieval-Augmented
RAG represents a paradigm shift in how we interact with information. By combining the reasoning capabilities of large language models with domain-specific knowledge retrieval, we can build systems that are:
Accurate: Grounded in actual documents
Transparent: Citations for every claim
Scalable: Handle thousands of documents
Cost-effective: Cents per query
User-friendly: Natural language interface
This project demonstrates that building production-quality AI applications is no longer the exclusive domain of large tech companies. With the right architecture and open-source tools, individual developers can create sophisticated systems that solve real problems.